 (Fig. 6)
(Fig. 6)
(Fig. 6)
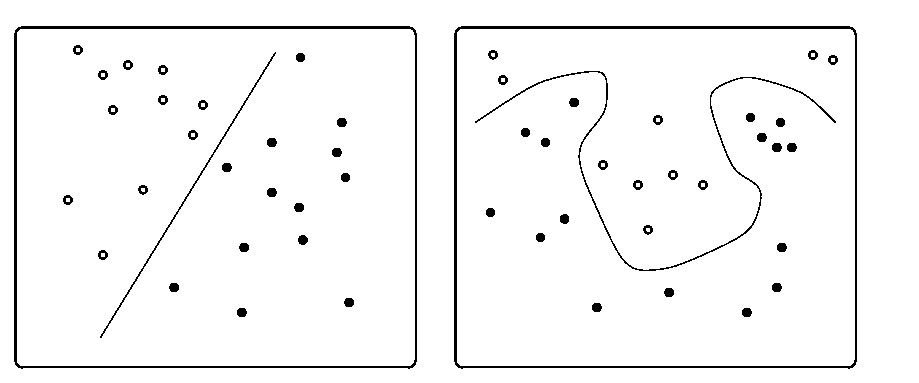
On the left side, a straight line can serve as a discriminant: we can place the line such that all filled dots lie on one side, and all unfilled ones lie on the other. The classes are said to be linearly separable. Such problems can be learned by neural networks without any hidden units. On the right side, a highly non-linear function is required to ensure class separation. This problem can be solved only by a neural network with hidden units.
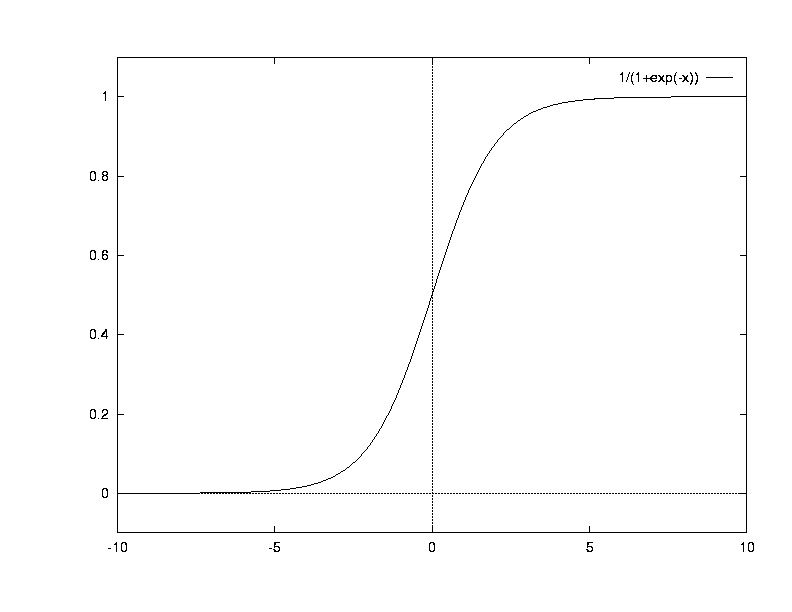
A network with linear output used in this fashion, however, will expend a lot of its effort on getting the target values exactly right for its training points - when all we actually care about is the correct positioning of the discriminant. The solution is to use an activation function at the output that saturates at the two target values: such a function will be close to the target value for any net input that is sufficiently large and has the correct sign. Specifically, we use the logistic sigmoid function
Given the probabilistic interpretation, a network output of, say, 0.01 for a pattern that is actually in the '1' class is a much more serious error than, say, 0.1. Unfortunately the sum-squared loss function makes almost no distinction between these two cases. A loss function that is appropriate for dealing with probabilities is the cross-entropy error. For the two-class case, it is given by

When logistic output units and cross-entropy error are used together in backpropagation learning, the error signal for the output unit becomes just the difference between target and output:
In other words, implementing cross-entropy error for this case amounts to nothing more than omitting the f'(net) factor that the error signal would otherwise get multiplied by. This is not an accident, but indicative of a deeper mathematical connection: cross-entropy error and logistic outputs are the "correct" combination to use for binomial probabilities, just like linear outputs and sum-squared error are for scalar values.
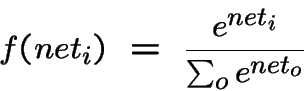
where o ranges over the n output units. The cross-entropy error for such an output layer is given by
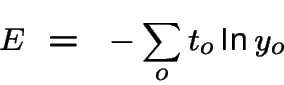
Since all the nodes in a softmax output layer interact (the value of each node depends on the values of all the others), the derivative of the cross-entropy error is difficult to calculate. Fortunately, it again simplifies to
so we don't have to worry about it.
{kind=link}